快速排序的一些总结
前言:最近又写到了有关快速排序的代码,结果半天写不对。从代码的整体上来说,代码结构是没问题的,就是在边界问题上出现了错误,经过一番思考以及查询资料,终于完美解决了,因此特地小记一下。
快速排序的一些总结
一. 简介
快速排序算法,它的基本处理思路就是:
- 先将数据分割成两部分:一份小,一份大
- 然后再分别对这两部分数据进行快速排序
以此达到数据的排序,其基本逻辑代码如下:
1 | // 这里采用闭区间 [left, right] |
二. 排序原理
快速排序最关键就是如何将数据分成大小两部分,也就是 partition 的逻辑。
先给出一份 partition 的代码,然后再进行说明:
1 | int partition(int[] a, int left, int right){ |
下面用一个例子来介绍一下 partition 的处理过程。
假设要对数组进行从小到大的排序:
(1) 首先给定需要排序的数组:
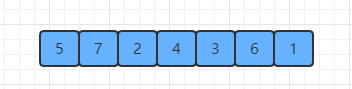
(2) 选定一个基准值,这里暂时使用左端的值(也就是5):
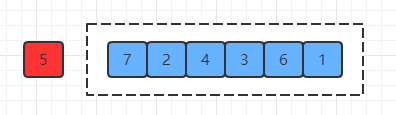
(3) 接着利用两个指针分别从数组左端和右端去遍历数据
- 左指针,找到比基准值大(> 5)的值时则停止
- 右指针,找到比基准值小(< 5)的值时则停止
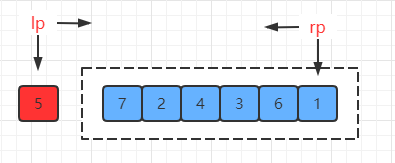
此时两个指针都停在了对应的位置,左指针指向7,右指针指向1:
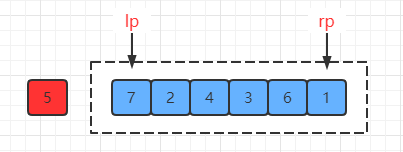
(4) 然后将这两个位置的数据进行交换:
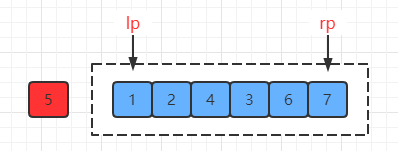
(5) 交换完成之后再执行第3步,直到两个指针相遇时结束交换:
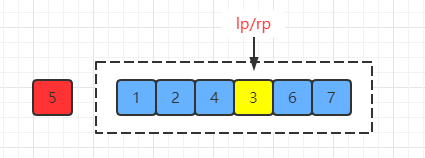
(6) 最后一步就是将指针相遇点的值与基准点的值进行交换:
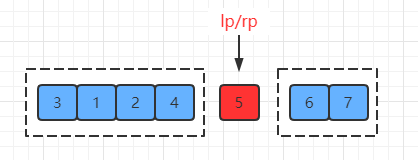
至此,partition 已经将数据分成了大小两部分(<5 和 >5)。
而基准值(也就是 5)也放在了最终排序结果中的正确位置。
也就是说,每一轮 partition 排序,都会将基准值放在它最终排序结果的正确位置上。
三. 基准点以及指针移动顺序
在上面的排序中,有几个比较关键的地方:
- 基准值的选取
- 基准点位置
- 指针的先后移动顺序
基准值的选取
基准值的选取没什么好说的,一般都是取左端或者右端的值。
如果对排序有其他要求的话,还可以用随机取值、三元取值(左端,中点,右端)等取值方法。
基准点位置
基准点,在数据分区前,一般都会将基准值放在数组的左端或右端,这两个位置就是基准点。
指针的先后移动顺序
指针的先后移动顺序指的就是谁先移动,谁后移动。
因为排序时两个指针会分别从两端往中间移动,所以移动顺序还是会对排序有影响的。
很明显,基准值只会影响排序的速度,而不会影响最终的排序结果,因此此处不讨论。
那基准点和指针先后顺序是否会影响排序的正确性呢?下面用例子来验证一下这个问题。
根据基准点和指针先后顺序,可以分为四种情况:
- 基准点左端,指针移动先右后左
- 基准点左端,指针移动先左后右
- 基准点右端,指针移动先右后左
- 基准点右端,指针移动先左后右
在验证这几种情况之前,先给出需要排序的数组:
假设要将数组按从小到大排序,并选取5为基准值。
3.1 例子演示
(1) 基准点左端,指针移动先右后左
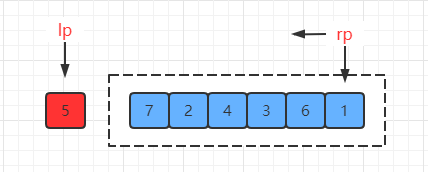
那么按照之前 partition 的逻辑,最终两指针相遇的位置如下:
最后交换基准值与指针相遇点的值:
至此,这里得到的结果没问题,后续执行也没有问题,就不贴图了。
(2) 基准点左端,指针移动先左后右
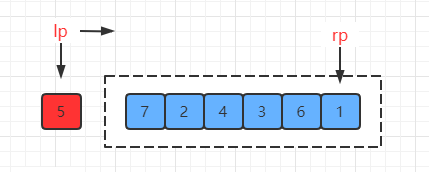
那么按照之前 partition 的逻辑,最终两指针相遇的位置如下:
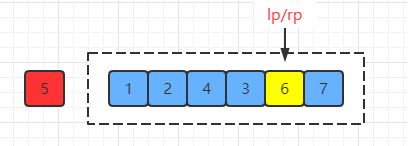
最后交换基准值和相遇点的值(注意,这里两指针相遇的位置变化了,之前是3,现在是6):
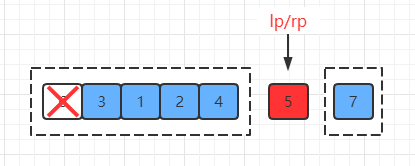
到这里就已经可以知道结果了,排序已经出错了。
再对另外两种情况(基准点在右端)分析的时候,也会发现:一种失败,一种成功。
这里就不再贴图分析了,下面来分析一下为什么会出现这种问题。
3.2 分析总结
要分析出现问题的原因,首先先要明确以下2点:
- 基准值在经过一轮排序之后,它所在的位置必定是在最终排序序列的正确位置
- 与基准值交换的值(也就是指针相遇的值)必须属于基准点所在的这一边
根据这两条规则,可以知道上面出现问题的原因正是指针相遇的位置不正确。
指针相遇的值不属于基准点这一边,导致与基准值交换之后出现排序错误。
那怎么保证最后指针能指向正确的位置呢?下面先给出结论:
- 基准点对面的的指针先走
下面对结论进行分析说明,假设选取基准点为左端。
(1) 如果是先移动右指针,再移动左指针
这种情况肯定是右指针先停止移动,左指针再停止移动。因此,
- 左右指针相遇时必然满足右指针的停止条件,相遇值必小于基准值
也就是说,此时相遇值是属于左端的,与基准点同一边,可以和基准值交换。
(2) 如果是先移动左指针,再移动右指针
这种情况肯定是左指针先停止移动,右指针再停止移动。因此,
- 左右指针相遇时必然满足左指针的停止条件,相遇值必大于基准值
也就是说,此时相遇值是属于右端的,与基准点不同边,是错误的位置。
同理,当基准点在右端时,先移动左指针,再移动右指针,也能够保证排序的正确性。
因此可以得出一个结论:
- 只有 **让基准点对面的的指针先走**,才能正确排序
根据这个结论,上面的代码是取左端为基准点,指针是先右后左,因此代码是没问题的。
四. 基准值的问题
这里讨论的基准值的问题指的是,当排序左右指针移动过程中:
- 如果遇到与基准值相等的值,此时是应该跳过还是停止?
关于这个问题,在上面的代码中,有两条关键语句:
1 | // 先右遍历取小值 |
需要注意的是 a[rp] >= x 和 a[lp] <= x 这两个地方:
- “>=” 和 “<=” 能不能换成 “>” 和 “<” 呢?
一样地,根据不同的大小符号,可以分为四种情况:
a[rp] > x,a[lp] < xa[rp] >= x,a[lp] < xa[rp] >= x,a[lp] <= xa[rp] > x,a[lp] <= x
下面用例子来对这几种情况进行说明。
4.1 例子演示
下面分别对这几种情况进行分析,代码依旧参考前面给出的代码。
(1) a[rp] > x,a[lp] < x
假如给出一个数组数据如下:
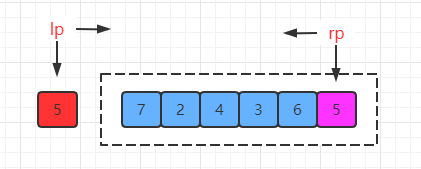
按照这个条件执行,左右指针根本不会发生移动,从而陷入死循环。
(2) a[rp] >= x,a[lp] < x
假如给出一个数组数据如下,并且左右指针已经完成一轮移动了,它们此时的位置如下:
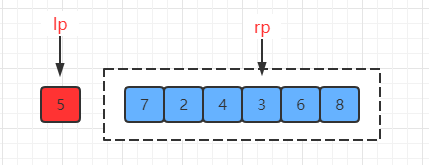
接下来就是交换两个指针指向的值,交换后:
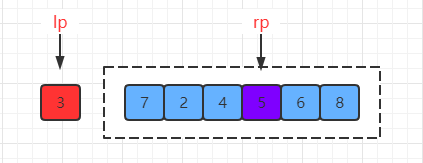
由于排序还没完成,紧接着进行下一轮移动,先移动右指针:
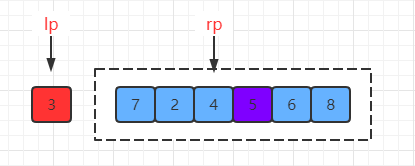
到这里已经发现问题了,基准值的位置丢失了!!!。
也就是说,此时把基准值的位置给弄丢了,那就无法拿到正确的分割点,最后排序肯定是失败的。
至于后面的两种情况,此处就不分析了,这两种情况是可以得到正确结果的。
4.2 分析总结
根据上面讨论中出现的情况,需要注意两点:
- 不能陷入死循环
- 不能丢失基准值的位置
为了避免这两种情况,必须在代码中实现以下两点:
- 有一边必须携带 “=”,才能够防止死循环;
- 带 “=” 的必须属于基准点这一边的指针(因为该指针是从基准点出发,不能让它把基准点交换出去)。
为了减少麻烦和不必要的错误,最简单的方法就是:
- 两边指针判断都带 “=”
而且,这样做还能保证分离的大小两部分数据的平衡性。
五. 总结
总的来说,写快速排序代码时,需要注意以下几点:
- 基准点对面的指针先移动
- 两边指针的判断条件都带 “=”(即等于基准值的位置,都跳过)
总之一句话,基准点对面的指针先移动,移动时都带 “=”。
参考
http://www.cnblogs.com/ahalei/p/3568434.html
https://blog.csdn.net/lemon_tree12138/article/details/50622744